
Vibe Coding a Real Mobile App: We Put 'Vibe Code' to the Test

The promise of "vibe coding" is intoxicating: speak your desires into existence without much thought, and a fully functional application materializes. It's a powerful dream, and platforms like Vibe Code App are marketing it aggressively.
But does it hold up when taken out of the "Tinder for Dogs" demo world and thrown at a real-world engineering problem?
My colleague Hamel Husain and I decided to find out. Our goal was simple but practical: build a mobile app to view and eventually annotate LLM evaluation traces from Arize Phoenix, a popular MLOps tool. It’s the kind of internal tool that’d be perfect for vibe coding, something you want for yourself but might not want to spend days building from scratch.
Here's a blow-by-blow of our journey, and a hard look at the gap between the vibe and the reality.
The Initial Attempt: Pure Vibe Coding
Following the playbook we've seen in their demos, we started with a simple, optimistic prompt. We asked Vibe Code to create a mobile app that could pull and render the 50 most recent traces from a Phoenix project, given a project ID and an API key.
The agent began its research but seemed to get confused, pulling up documentation for Phoenix datasets instead of traces and citing endpoints that didn't quite seem right. It was building an entire app (UI components, state management stores, navigation) without first securing the foundation: a successful API call.
After a lengthy generation process, it produced an app that looked the part but failed at the first hurdle.
The connection failed. The app couldn't get the actual traces from Phoenix.
The Intervention: Giving It the Answer Key
Alright, "pure vibe coding" was a bust. But what if we gave it a helping hand?
Hamel wrote a minimal, dependency-free JavaScript script that successfully connected to the Phoenix API and fetched the traces. We tested it. It worked perfectly. We then fed this working code back to the Vibe Code agent and said, "Something is still wrong. Here is a script that works. Please use this to fix the app."
This should have been a slam dunk. We weren't asking it to discover anything new; we were asking it to integrate a proven solution.
The agent went back to work, refactoring and rebuilding. The result?
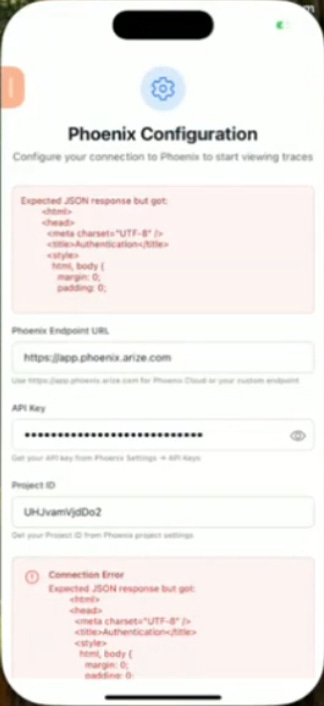
A new error. The app was not only broken but arguably more broken than before. It had taken a working script and produced a syntax error. This was a critical failure. Even when given the exact answer, the "vibe" wasn't enough to translate it into a functional mobile app.
From Vibe to Validation: The Engineering Approach
Our experiment shows a crucial lesson about the current state of AI-assisted development. While "vibe coding" tools are fantastic for simple, in-distribution tasks, they often lack the robustness and iterative debugging capabilities required for custom, real-world applications.
Building robust, production-ready AI systems requires a two-pronged engineering approach: a disciplined process for building and a rigorous framework for evaluating.
The failure of Vibe Code wasn't just a development failure; it was an evaluation failure. It couldn't build the app, and it had no way to test itself to even know it was broken.
That's why we've designed two complementary courses to give you the complete skillset for professional AI engineering.
1. Master the Build Process with Elite AI Assisted Coding
If your challenge is moving beyond simple prompts to build complex, enterprise-grade AI systems, this course is for you. It's about structuring the development process itself.
Instructors: Taught by industry leaders Eleanor Berger (ex-Microsoft, ex-Google) and Isaac Flath (ex-Answer.ai).
Outcomes: Learn to build a universal AI setup without vendor lock-in, design agentic workflows for CI/CD, and apply enterprise-grade practices for security and auditability.
Next Cohort: The next cohort runs from Oct 6–24, 2025, for
$1,500$1,050 USD. Discount ends soon.
2. Master the Evaluation Process with AI Evals For Engineers & PMs
If you're building AI applications and find yourself asking, "How do I even test this?" or "If I change the prompt, how do I know I'm not breaking something else?", this course provides the answers. It's about ensuring the AI you build actually works.
Instructors: Taught by ML experts Hamel Husain and Shreya Shankar, with 25+ combined years building & evaluating AI systems.
Outcomes: Learn to bootstrap with synthetic data, create data flywheels, automate evaluation with methods you can actually trust (like LLM-as-a-judge), and avoid the most common mistakes seen across dozens of AI implementations.
Next Cohort: The next 4-week cohort starts Oct 6—the last live cohort of the year.
Whether you need to level up your AI development process or your evaluation framework, we've got you covered. Stop hoping the vibe is right. Learn the principles to engineer success every time.