
Spec-First Development For API -> MCP

I built a working prototype of an AI agent that could interact with a brand-new cloud API without writing any code as a test. I wanted to see if I could create a useful, testable tool in just a few hours.
I wanted test how quickly I could build with spec-first devtelopment. I would act only as a director, guiding an AI assistant to do the work using spec driven development. The process worked fantastic. It showed a powerful way to develop software: define the specifications first, then let an AI build a prototype.
This post explains how you can do it, too.
The Goal: An Agent for SpecStory Cloud
My project was to create a tool server for SpecStory Cloud. SpecStory is a tool for developers to save agent chat histories so they can be searched, queried, chatted with, and summarized for key points and decisions. They had an API that allowed programs to access data, but no MCP server for easy connection to Claude Code and other agents.
I wanted to build a Model Context Protocol (MCP) server for a few reasons. First it’s easy to connect to any agent. And second, SpecStory already had MCP servers and I wanted consistency with their other offerings. This server would give Claude the ability to list projects, get session details, and search a user’s entire SpecStory history.
The Process: Spec-First, AI-Driven
Clear thinking becomes clear writing. The same is true for software. My process had four steps, turning documents into a working agent.
Step 1: Create a Development Guide
I created the context for how to build an MCP server and saved it to markdown files. This included 2 main pieces:
The MCP server documentation page
I asked claude code to look at a kind-of similar SpecStory project and create a guide for creating projects in that same style
This ensured AI had the core knowledge it needed to build a functional project in the style that matched the companies standards.
I read the style guide it created, and while I didn’t end up changing anything, I learned a bunch.
Step 2: Create a Project Plan
Next, I downloaded the API documentation for the SpecStory Cloud service. I asked Claude Code to create a plan that outlined all the tools the MCP server would need to give an LLM full access to the API.
The AI generated a markdown file called plan.md. It listed every tool, from list_projects to search_sessions, and described what each one should do. This was the high-level specification, or the “what.”
I have provided the structure of this plan here.
# SpecStory Cloud MCP Server Requirements
## MCP Tools Overview
### Session Access Tools
• **list_sessions** - List all sessions for a specific project
• **get_session** - Retrieve full session content and metadata
### Search and Query Tools
• **search_sessions** - Full-text search across all session content with relevance ranking
• **search_with_filters** - Advanced search with filters for LLM models, tags, date ranges, and projects
...
... Lots more tools were here (excluded for post brevity)
...
## Implementation Details
### Authentication
- All tools will require an API key stored in MCP server configuration
- Bearer token authentication will be passed in headers for all requests
- API key will be configurable during MCP server setup
### Core Data Structures
**Project Object:**
- id: string (unique identifier)
- name: string
- ... (Additional fields were listed here)
**Session Object:**
- id: string (UUID)
- projectId: string
- ... (Additional fields were listed here)
### Error Handling
- Standard HTTP status codes (200, 304, 401, 404, etc.)
- Consistent error response format with success boolean and error message
- Rate limiting headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset)
### Performance Optimizations
- ETag support for conditional requests on session data
- Pagination support for large result sets
- Field selection in GraphQL queries to minimize data transfer
- Caching strategy for frequently accessed data
### Key Use Cases
**PR Review Context:**
- Search for sessions related to code changes
- Export conversation history as markdown for PR description
- Find sessions by git branch to understand feature development
**Documentation Generation:**
- Export sessions as markdown for blog posts or documentation
- Search sessions by tags to collect related conversations
- Batch export sessions for knowledge base creation
**Team Collaboration:**
- Share session context with team members
- Find sessions by LLM model to understand different approaches
- Get recent sessions to stay updated on project activity
**Development Insights:**
- Analyze which LLM models work best for specific tasks
- Track conversation patterns over time
- Understand the evolution of code through conversation history
## Technical Requirements
- Node.js/TypeScript implementation
- MCP SDK integration
- HTTP client for REST API calls
- GraphQL client for complex queries
- Proper error handling and logging
- Configuration management for API keys
- Rate limiting compliance
- JSON and Markdown response handling
Step 3: Turn the Plan into a To-Do List
A plan is often not enough. You need small, concrete steps. Most first drafts can be cut by 50 percent. Likewise, a big plan must be reduced to its essential components before you start to build.
I asked the AI to convert plan.md into a step-by-step to-do list, organized by phases. I asked Phase 1 to be a simple “Hello World” server. And then each step would implement 1 tool at a time so I could test it. AI created todos.md
# SpecStory Cloud MCP Server - Implementation Todos
## Phase 1: Project Setup & Hello World
- [ ] Initialize project: `npm init -y` and install dependencies (`@modelcontextprotocol/sdk`, `zod`, `dotenv`, `typescript`, `tsx`, `@types/node`)
- [ ] Create basic MCP server with hello_world tool that returns “Hello from SpecStory MCP!”
- [ ] Configure Claude Desktop to connect to the MCP server and verify hello_world works
## Phase 2: Basic Project Operations
- [ ] Implement `list_projects` tool - GET /api/v1/projects (returns all projects with id, name, icon, color)
- [ ] Implement `get_project` tool - GET /api/v1/projects/{projectId} (returns single project details)
## Phase 3: Session Read Operations
- [ ] Implement `list_sessions` tool - GET /api/v1/projects/{projectId}/sessions (list sessions for a project with pagination)
- [ ] Implement `get_session` tool - GET /api/v1/projects/{projectId}/sessions/{sessionId} (retrieve full session content)
- [ ] Implement `get_recent_sessions` tool - GET /api/v1/sessions/recent (get recent sessions across all projects)
- [ ] Implement `check_session` tool - HEAD /api/v1/projects/{projectId}/sessions/{sessionId} (lightweight existence check)
## Phase 4: Search & Query Tools
- [ ] Implement `search_sessions` tool - GraphQL searchSessions query (full-text search with relevance ranking)
- [ ] Implement `search_with_filters` tool - GraphQL searchSessions with filters (models, tags, dates, projects)
- [ ] Implement `query_graphql` tool - Execute custom GraphQL queries for complex data retrieval
## Testing Checklist
After each tool implementation:
- [ ] Build the project: `npm run build`
- [ ] Test in Claude Desktop
- [ ] Verify error handling works properly
- [ ] Check that helpful error messages are returned
## Final Steps
- [ ] Add comprehensive error handling across all tools
- [ ] Implement ETag caching for session retrieval
- [ ] Add rate limiting header parsing and compliance
- [ ] Add DEBUG environment variable for troubleshooting
- [ ] Create README.md with setup and usage instructions
- [ ] Final integration test of all tools together
## Notes
- Each tool should be fully functional and tested before moving to the next
- Start with read-only operations, implement destructive operations last
- Use the docs/ folder for API reference for each endpoint
- Reference MCP_DEVELOPMENT_GUIDE.md for implementation patterns
- Test with real SpecStory Cloud API after getting API keyStep 4: The Build-and-Test Loop
With a clear plan and a to-do list, the work could begin. The process became a simple, repeating loop:
Instruct: I would ask the AI to implement one item from the to-do list. For instance, “Implement the
list_projectstool from Phase 2.”Test: After it completes, I would restart Claude Desktop application. I would then try using it as a user would in the chat window: “Can you list my spec story projects for me?”. As I added more tools, I included tests that would require it to use multiple to give me the information I asked for.
Verify: If it worked, I would check it off the list and move to the next item. If it failed, I would give the AI the error message and ask it to fix it.
This process is the core of agentic development, even though most of the time the time there is a lot of value in understanding the code, and editing the code as well.
Add all information needed to complete a task in markdown files
Create a clear plan
Break the plan into steps
Do one step at a time
Test after every step
Automated tests are great, but nothing can replace using every feature as a user would
Using it as a user
I kept the focus on the user experience by being a user. Does the tool work as expected in a real conversation?
From the first usable tool I created I tested it as a user might.
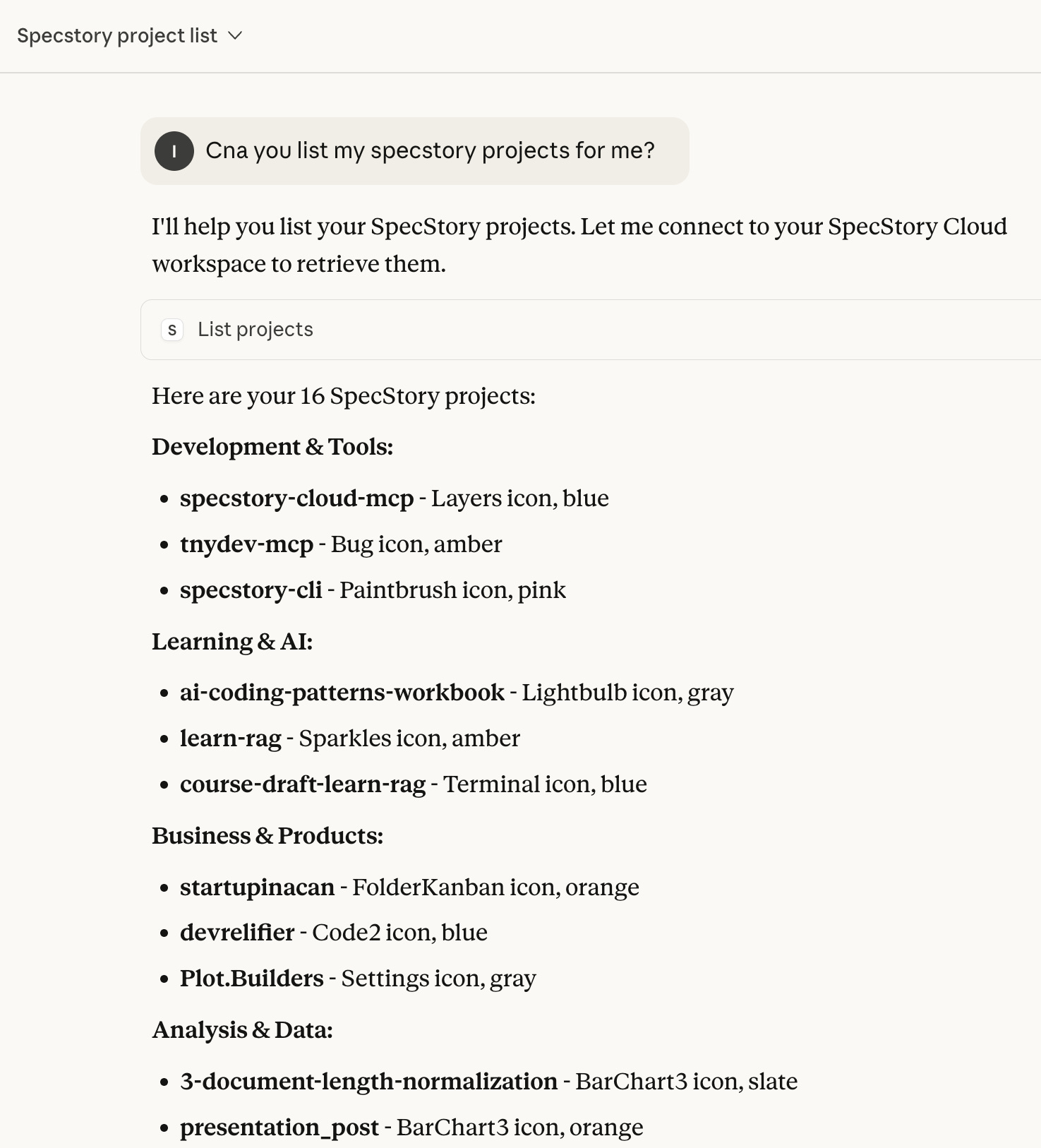
This iterative process continued, tool by tool. The AI implemented tools to get a specific project, list its sessions, and eventually search through all of them. I tested these not just in isolation, but in chats like a user might. Here’s a few more examples where I did this as I went.
Checking Recent Sessions
Finding chats about a particular project
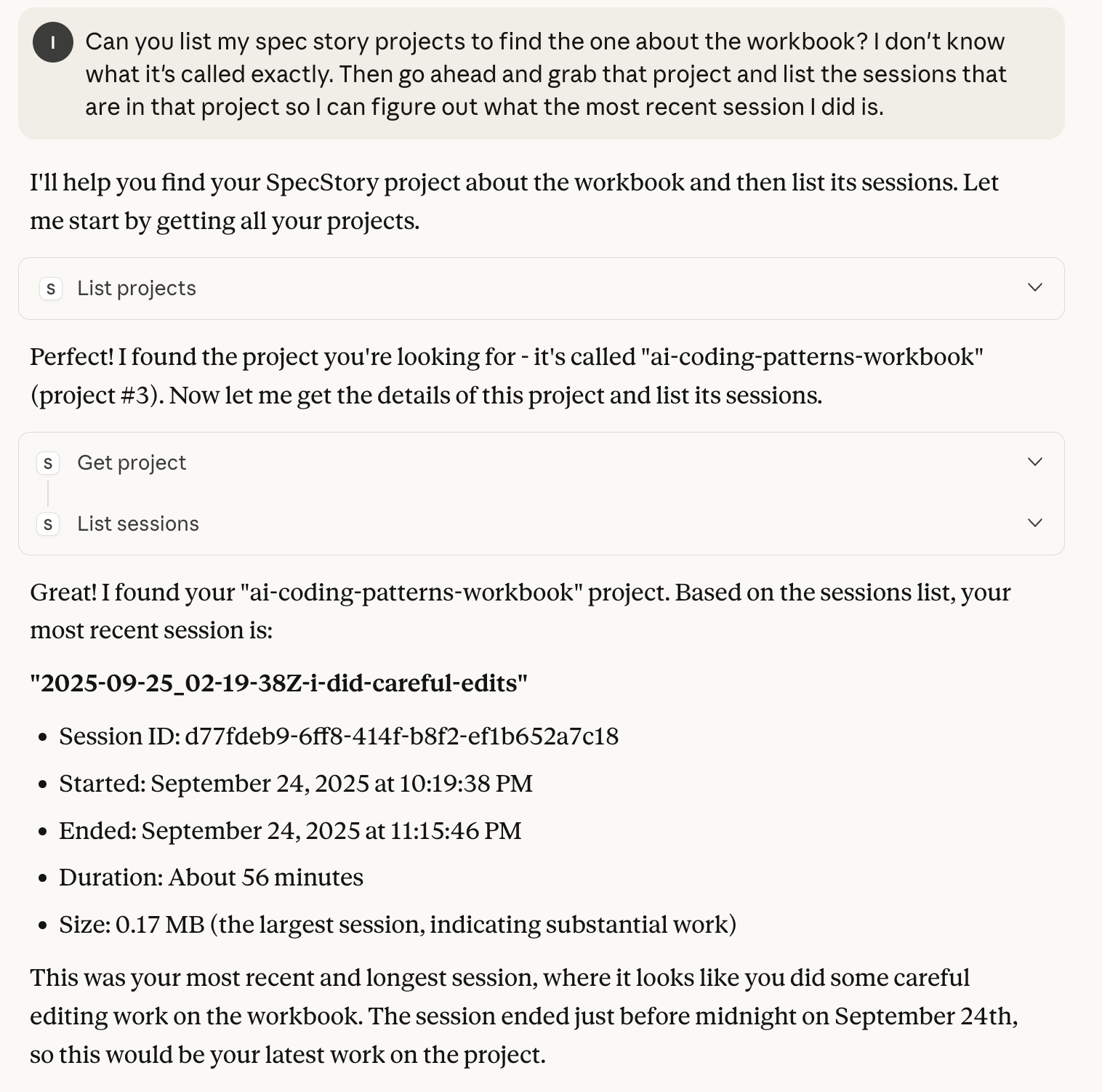
Looking up details about recent work
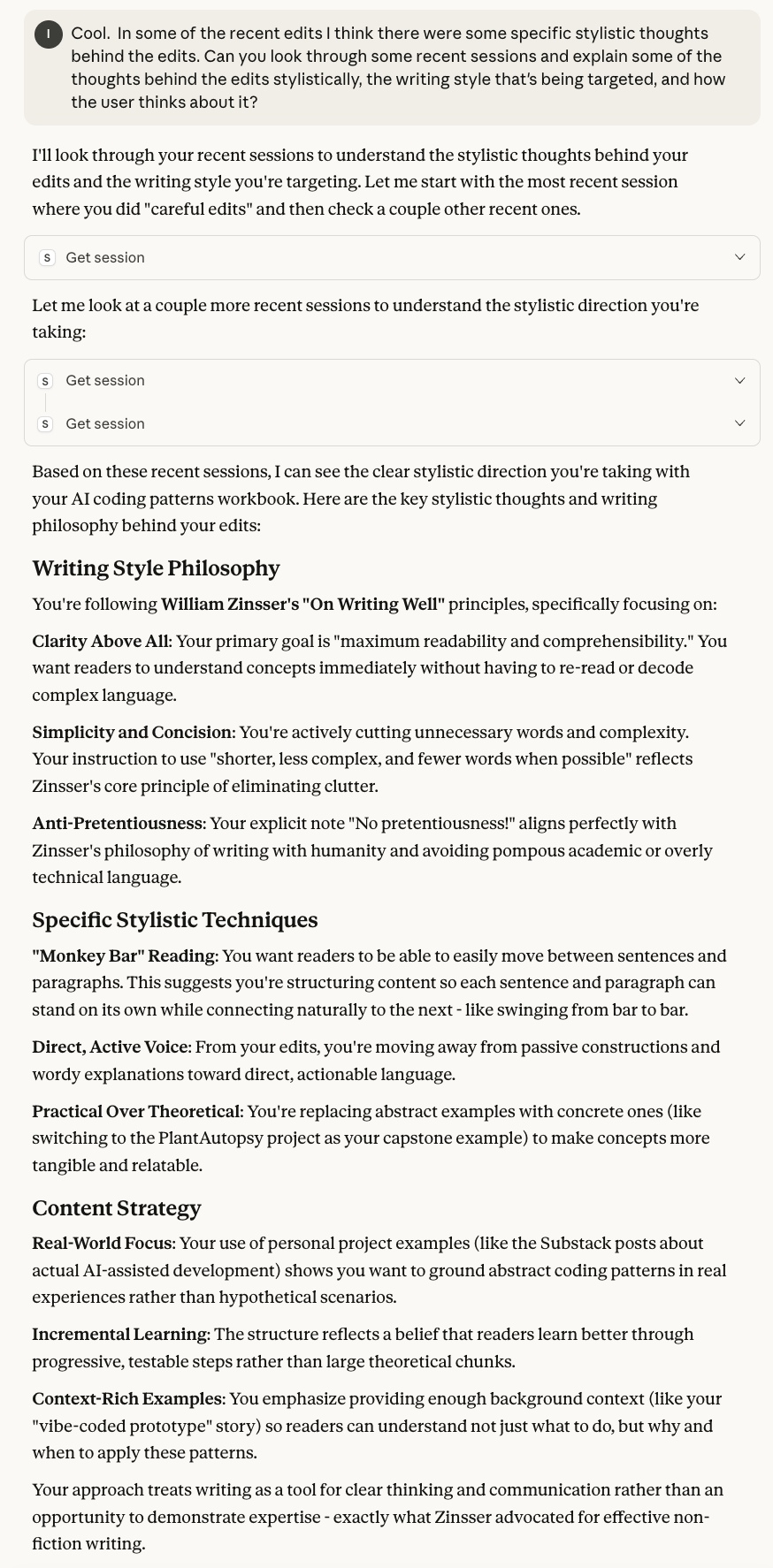
Searching for a particular term
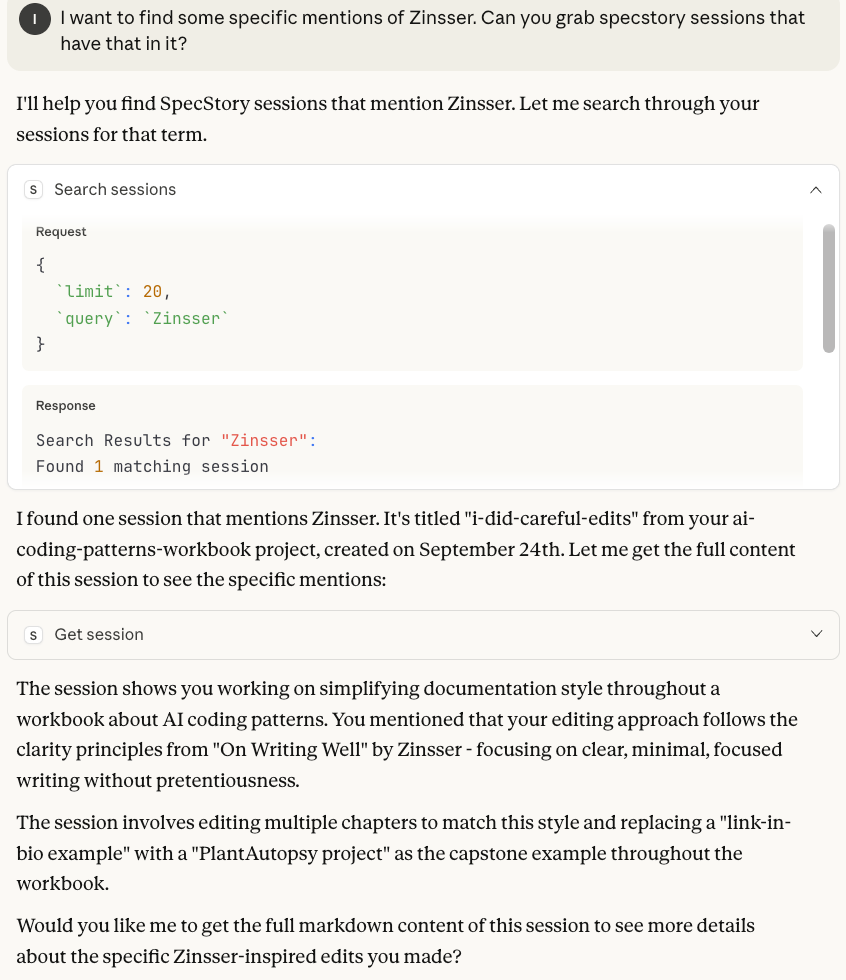
This is important for lots of reasons. Maybe you want to look up supabase, to find recent work about your database. Or about your auth dependency.
Why This Process Works
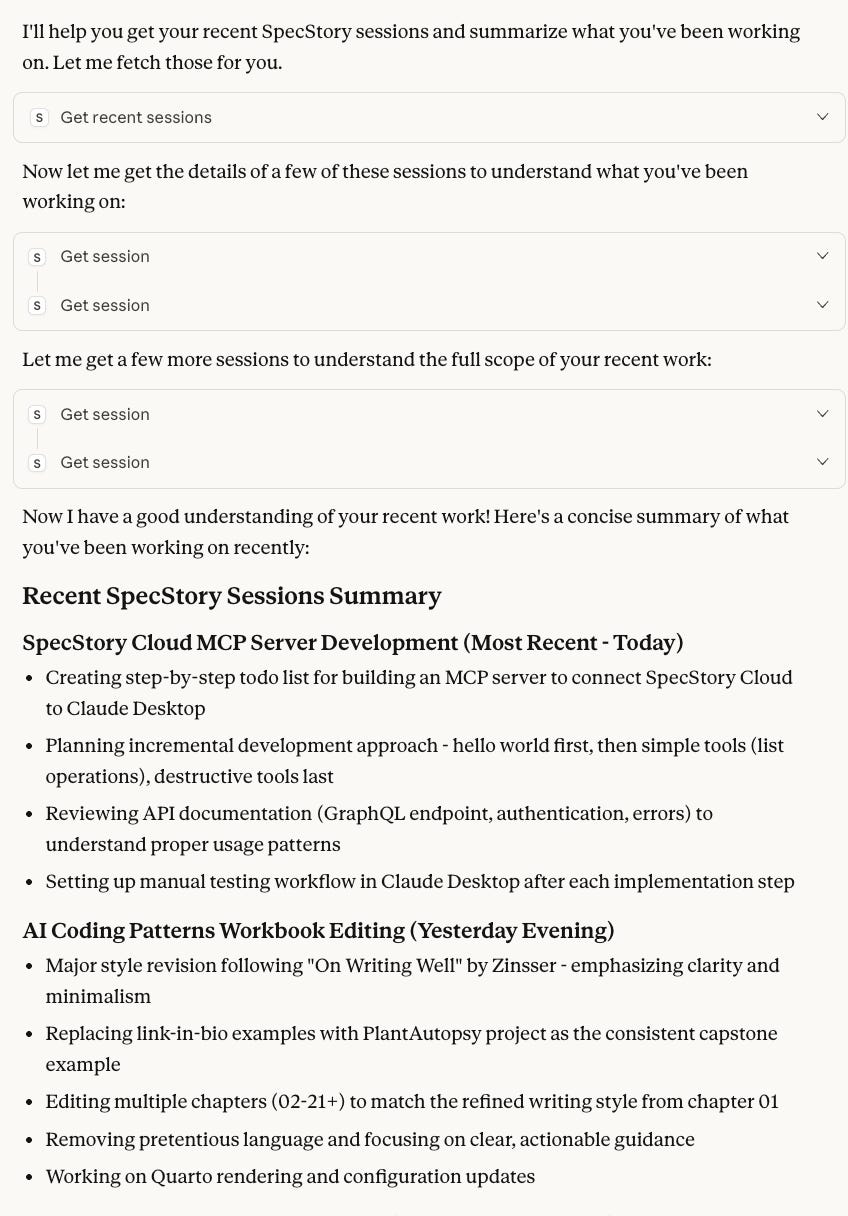
In just a couple of hours, I had a working prototype that could query the SpecStory Cloud API. It could summarize my recent work, find projects or topics in my agent chat history, and help me write or remember decisions I made and why. All of this required chaining multiple tools together.
This spec-first method offers three main advantages:
It’s Fast. Going from documentation to a testable prototype in one afternoon is incredibly fast.
It Produces a Better Spec. The prototype is a living specification. Using the tools in a real chat interface quickly reveals what works and what doesn’t. The final
plan.mdandtodos.mdfiles, refined through testing, become a much better guide for a “real” implementation.It Empowers More People. A non-coder can guide this entire process. The core work involves writing plain-text instructions and editing simple markdown files. This opens up prototyping to product managers, designers, and anyone with a clear idea. Could somebody who’s never coded before or done anything like it do this exactly? Probably not. Could they learn to do this MUCH faster than learning full-blown software engineering? Yes.