
OpenHands v1 & You

In a recent talk, Ray Myers, Chief Architect at Open Hands, provided a deep dive into the Open Hands project, detailing its evolution, its upcoming V1 release, and the strategic pivot toward a modular Agent SDK. Ray framed Open Hands as “the leading open-source coding agent,” a project that began 18 months ago and has since developed a robust ecosystem.
The Open Hands V1 Vision: From Monolith to SDK
Ray began by showcasing the existing Open Hands interface, a comprehensive tool that integrates a chatbot, terminal, browser, and code editor. While powerful, he noted a core design tension for the V1 release.
We wracked our brains on this and an important decision was made that there should be infinite cool stuff in V1... But there’s another important design constraint because all of the cool stuff in V0 was already quite big. So, V0 was already too big. We need V1 to be available in a way that is much smaller and yet still have infinite cool stuff.
The solution, Ray explained, was modularity. The core agent engine has been extracted into its own package, the Agent SDK. This allows the existing Open Hands application to depend on this engine while also enabling developers to import the SDK directly to build their own custom agentic behaviors.

Why Open Source is Essential
This move underscores the project’s open-source philosophy. Ray argued that true extensibility can only come from an open-source model.

Infinite cool stuff can only come from open source. Any proprietary player may wish to give you a lot of customizability... but they are always going to be somewhat limited in the package they provide you.
He then detailed the project’s origin story, which began in March 2024 as OpenDevin in response to the viral Devin demo. The repository, started as a “call to the community,” quickly gained momentum, passing 64,000 GitHub stars.
Ray shared the motivations of the project’s founders:
Dr. Graham Neubig: To reduce the “duplicate effort” of countless companies and academic labs all trying to build the same thing.
Robert Brennan (CEO): A belief that developers prefer open-source tools and that “this technology is too powerful to be held in a closed way by a single entity.”
Xingyao: To ensure reproducibility in research and create a “collective code base” that prevents promising research prototypes from being abandoned.

Ray also shared his own journey, having started the “No Pilot” manifesto to champion open-source agents as essential infrastructure. He believes openness is the antidote to the fear and confusion surrounding AI’s impact on software engineering.
People are afraid of what is in the black box... I think [that] is really helped by some examples where we can say, “No, you can open it up. You can understand exactly what this is and how it works.”

Defining a “Leading” Agent
To substantiate the claim of Open Hands being “leading,” Ray pointed to three areas:
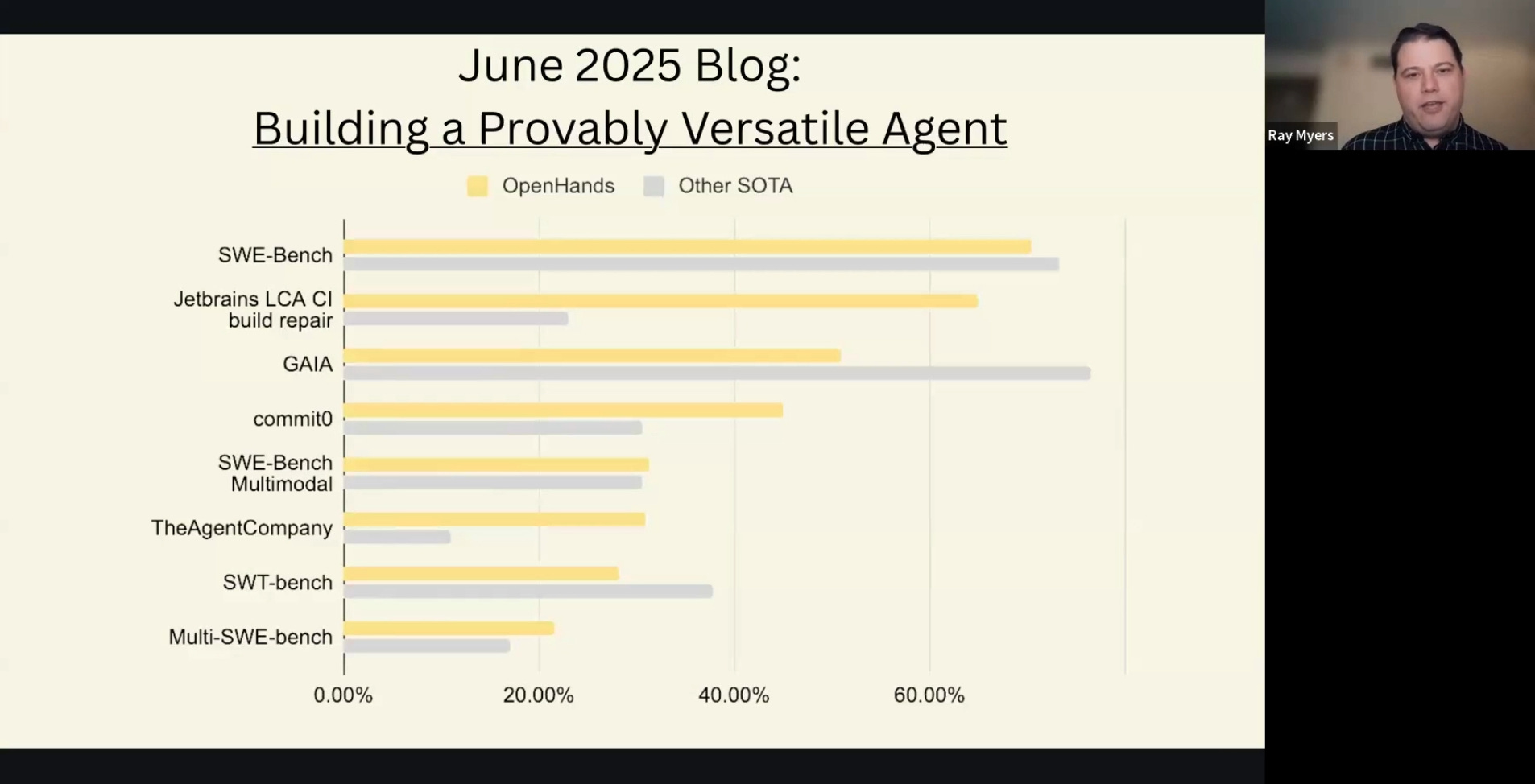
Benchmarks: Strong performance on standards like
SWE-bench(addressing real GitHub issues in Python libraries),Multi-SWE-bench(expanding to more languages), andSWT-bench(unit test creation).Community Momentum: The rapid growth in stars and contributors.
Original Research: The team actively publishes its findings.

He cited a June 2025 paper, “Coding Agents with Multimodal Browsing Are Generalist Problem Solvers,” which detailed performance gains from adding multimodal (vision) browsing and a dedicated search API.
We published it. We published how we did it. So, other people can learn from it even if they’re not using Open Hands.
A Technical Deep Dive: What is a Coding Agent?
Ray then demystified the architecture of a coding agent, defining it as “some LLM calls, in a chat loop, that can use tools, and those tools are relevant to coding.”
He broke down the core components:
The LLM Call: The baseline capability of interacting with a large language model.
The Chat Loop: The agent code responsible for maintaining the conversation history. This loop manages the “sleight of hand” that gives the stateless LLM a memory of the interaction, often condensing the history to fit the context window.
Tool Use: The key breakthrough, outlined in the 2023 ReAct (Reasoning and Acting) paper. The LLM is prompted to respond not with an answer, but with a request to call a specific tool.
Tool Execution: Ray noted this as a non-trivial component, pointing out that “multiple entire startups... are just dedicated to providing isolated execution environments for agents.”

A coding agent, he continued, is simply an agent whose tools are specific to software development. He referenced the 2024 Swe-agent paper as a key resource. These tools typically fall into four categories:
Navigation: Tools like
search,ls,cd, and a file opener that intelligently chunks files to manage the context window.Editing: Tools that can replace specific chunks of code, often identified by line numbers.
Execution: The ability to run commands, ideally in an isolated environment like a Docker container.
Knowledge: Web browsers, internet search, or specialized documentation search tools.

The SDK: Taking Agents Beyond the IDE
With this technical foundation, Ray explained why the Agent SDK is so critical. While agents inside an IDE are useful, the software development lifecycle extends far beyond writing code.
If you put an agent in IntelliJ or in VS Code, then you’re over here where we are coding. But... perhaps at your company, you code in IntelliJ, and then you build it in GitLab, and then you test it using Playwright, and then you release it using Argo to Kubernetes, and then you monitor it in Datadog, and then you’re making tickets... in Jira.
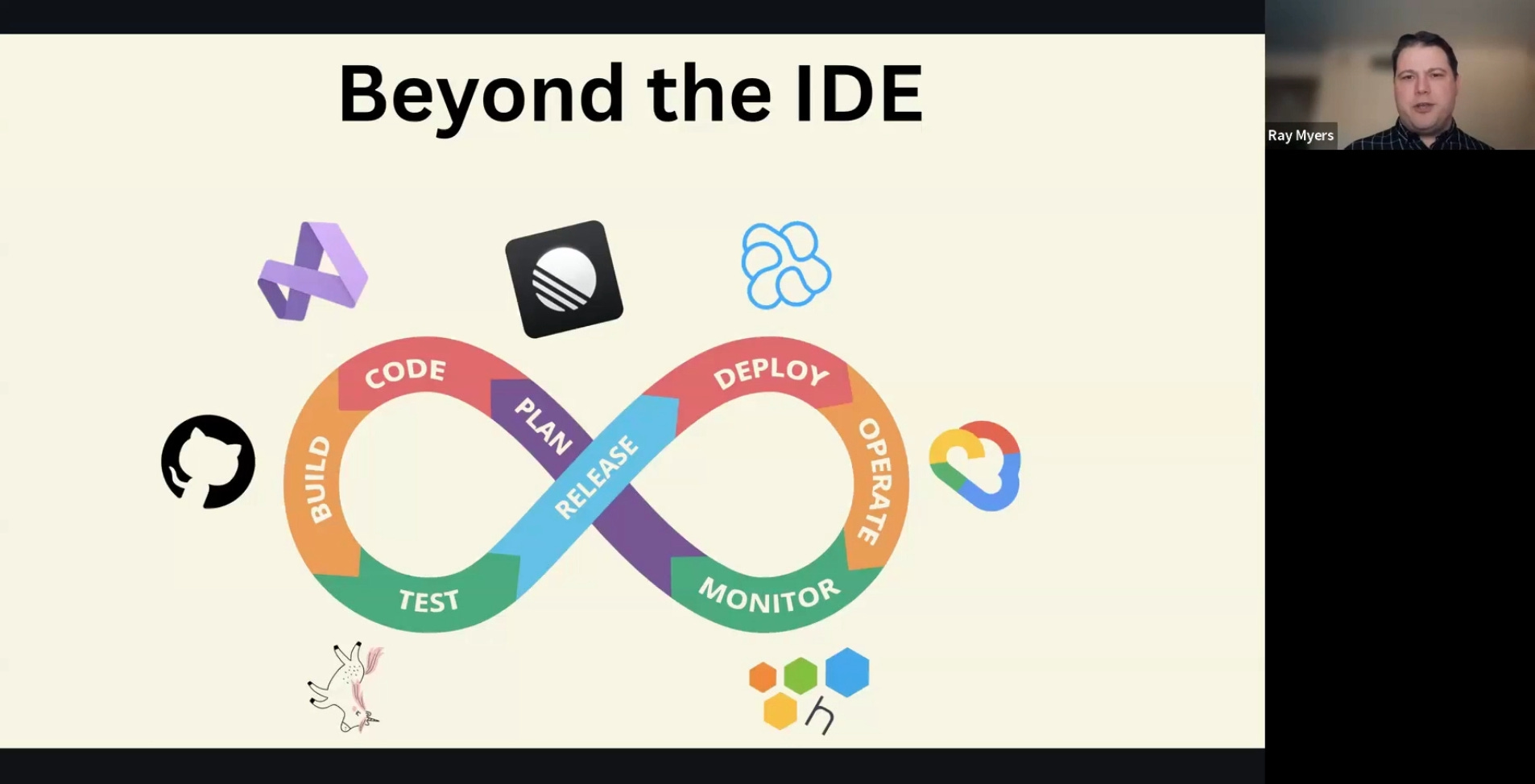
Because every company has a bespoke workflow, a one-size-fits-all packaged agent is insufficient. The Agent SDK allows developers to build agents that live where they are needed and are equipped with custom tools for their specific stack.
Ultimately, coding agents must go where you need them... and they must do what you need them to do with your bespoke needs.
Ray demonstrated this by showing an example from the SDK’s examples folder, custom_tools, where an agent’s capabilities were limited to only a grep command. He then shared his own experiment: building a custom tool that integrates with the Datadog client SDK to kick off log searches, enabling an agent to help with troubleshooting.

He concluded his presentation with a challenge to the community: to build a TDD (Test-Driven Development) agent.
There have been a lot of people... prompting agents to do test-driven development, and they often say, “Oh, but it didn’t actually strictly follow my instructions.” So, what something like Agent SDK allows you to do is customize what you’re allowing the agent to do... you have a lot more fine-grained control.
Community Discussion and Q&A
The presentation was followed by a Q&A session that explored several key challenges in the agent space.
On SWE-bench Saturation
Jim asked why performance on SWE-bench Verify (a subset of problems deemed solvable) is still under 80% and what this reveals about current limitations.
Ray replied that he views the benchmark as “somewhat saturated,” suggesting diminishing returns.
In between when agents were doing like 30% numbers and these 70-80 numbers, yeah, huge change in our user experience, but I don’t think by getting from 80 to 90, we we actually do better. I think we need other benchmarks that make up for what’s lacking... to be our improvement points going forward.
Jim agreed but noted the unsolved problems are still indicative of hard limitations. He reiterated his belief that TDD is the path forward, which Ray endorsed, adding that SDKs allow developers to “more strictly integrate the things that we know” rather than “just limited to prompting.”
The Jupyter Notebook Problem
Eleanor raised the issue of Jupyter notebooks, a critical environment for many developers where agents still struggle.
Ray acknowledged the challenge, noting a “culture clash” between academic users who rely on notebooks and industry patterns for large codebases.
There are things I really love about notebooks, but I don’t understand how this applies to large code bases... I guess I only have questions. I don’t have a lot of answers, but I think the fact that notebooks do resemble an agent trajectory is somehow important to this.
Jim suggested that notebooks could serve as the “UI” or “chat interface” for agents, primarily for “capturing those trajectories” and ensuring reproducibility.
Human-in-the-Loop (HITL)
Ethan asked about mechanisms for human-in-the-loop validation and fail-safes, such as limiting the number of times an agent can attempt an action.
Ray responded that this is a “very constant challenge” that has proven “not very amenable to one-size-fits-all solutions,” which is precisely why the SDK is the correct approach.
Anytime a tool call is made... you could say, “Hey, this isn’t authorized. You need to go get permission to do that.”... by customizing the tools... you can wrap the packaged tools... with... my custom checks and then just delegates to the out-of-the-box tool.
Jim added that the repository contains a confirmation_mode example and that the agent has an optional Risk Analyzer stage to evaluate a proposed action’s risk.
The talk concluded with Ray directing attendees to the Agent SDK repository at github.com/openhands/agent-sdk and the project’s main website at openhands.dev.