
OpenAI GPT-OSS
A Hands-On Mini Review of the New Open Models from OpenAI

OpenAI has made waves in the AI community by releasing GPT-OSS — their first open-source language models in approximately six years. This release marks a significant shift for the company, offering two variants under the permissive Apache 2.0 license:
GPT-OSS-120B: A 117 billion parameter model with 5.1B active parameters at inference
GPT-OSS-20B: A smaller 21 billion parameter variant
Testing the Model: Building a LISP Interpreter
To evaluate GPT-OSS-120B's capabilities, I chose a familiar task: creating a LISP interpreter. Back in the summer of 2002, I spent several weeks learning about compilers by writing a LISP compiler myself. Knowing that AI can now accomplish in minutes what took me weeks is something I find genuinely delightful.
This task has become one of my go-to benchmarks for testing new models' coding capabilities. I've previously used it to evaluate:
Qwen3 Coder — creating a Rust-based LISP interpreter
Gemini 2.5 Pro — building a JavaScript in-browser implementation
It's an ideal test because while it's not rocket science, it's also non-trivial — complex enough that the model likely hasn't memorized an exact solution.
The Development Process
I was eager to put the new model to the test. Since it was immediately available on OpenRouter, I figured I'd just prompt the OpenRouter chat to see what results I could get. I chose the larger 120B parameter model and started with a deliberately simple prompt.

The model ran incredibly fast. OpenRouter dispatches requests to fast inference cloud providers like Groq and Cerebras, and the response came in a fraction of a second. The model immediately provided both a description of the LISP interpreter it had created and a complete .go file. It looked amazing.

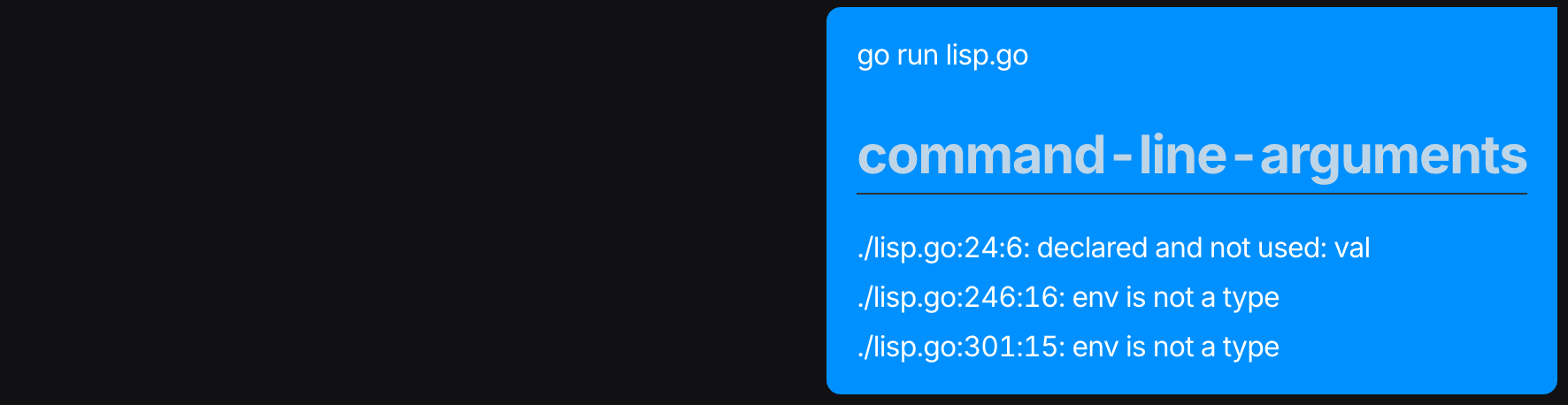
I copied the contents of the Go file, saved it, and ran it with go run — only to immediately encounter errors. Not perfect on the first run, but that's okay. I didn't do any special prompting, instead I simply copied the error messages and pasted them directly back into the chat.

The model thought for a little over a second this time, then returned what it claimed was a fixed version. Once again, I copied the results into my Go file and ran it. More errors appeared. And once again, without any elaborate prompting or explanation, I just copied those errors and pasted them into the chat.
This produced another version — and for the first time, the interpreter actually worked! I could run it successfully. However, when I tried to use it, I discovered it had some issues. It seemed that several built-in functions (operators in LISP) weren't implemented properly.
Following my established pattern, I copied the entire transcript of my attempt to use the interpreter and pasted it into the chat. GPT-OSS-120B thought for less than a second, explained what it believed the problems were, and created a new version. This iteration had a couple more errors, which I dutifully copied and fed back to the model.

Finally, on this iteration, it created a version that worked perfectly for me. The entire process — from initial prompt to fully functional Lisp interpreter — took just a handful of back-and-forth exchanges, each completed in seconds rather than minutes.
See the final version of the working interpreter in this gist.
Key Observations
Strengths
Blazing fast inference: It's hard to describe how fast this was — every iteration with a lengthy Go file and reasoning completed in 1-2 seconds
Strong coding capabilities: Successfully created a working interpreter through simple iteration
Excellent error correction: Understood and fixed issues from raw error messages alone
Cost-effective: Very competitive pricing for the performance level
It didn't produce perfect code on the first attempt, but this wouldn't be a problem with a proper coding agent that could iterate over problems and refine solutions.
Performance Analysis
The model demonstrates near state-of-the-art performance on public benchmarks despite its "modest" size. As a Mixture of Experts (MoE) model with low active parameters, it achieves:
Efficient execution on consumer hardware
Performance comparable to much larger state-of-the-art models
Super-fast inference through optimized providers
Practical Implications
For developers and organizations, GPT-OSS represents a compelling option:
Open source flexibility: Apache 2.0 license allows commercial use and modification
Hardware efficiency: Can run inexpensively on consumer hardware
Speed advantage: Enables rapid prototyping and real-time coding assistance
Cost benefits: Lower operational costs compared to proprietary alternatives
Conclusion
GPT-OSS marks a significant milestone in open-source AI development. The sheer speed of inference creates a powerful experience that fundamentally changes how we can interact with AI for coding. Given the very low price and lightning-fast inference, this is something I would seriously consider using for my own coding tasks in an agent setup.
While I didn't get to test how the model would perform in a proper agentic situation with tool calls and repeated iteration over problems, it shows tremendous promise. For developers seeking fast, capable, and cost-effective AI assistance, GPT-OSS delivers an exciting glimpse of what's now possible with open models.